查询环境顺序说明
写在最前
指标的查询中,会存在多处涉及到数据的筛选。
!!! note "为了便于更简单的描述查询的运行环境,本文会将分组的维度理解为一个筛选维度。
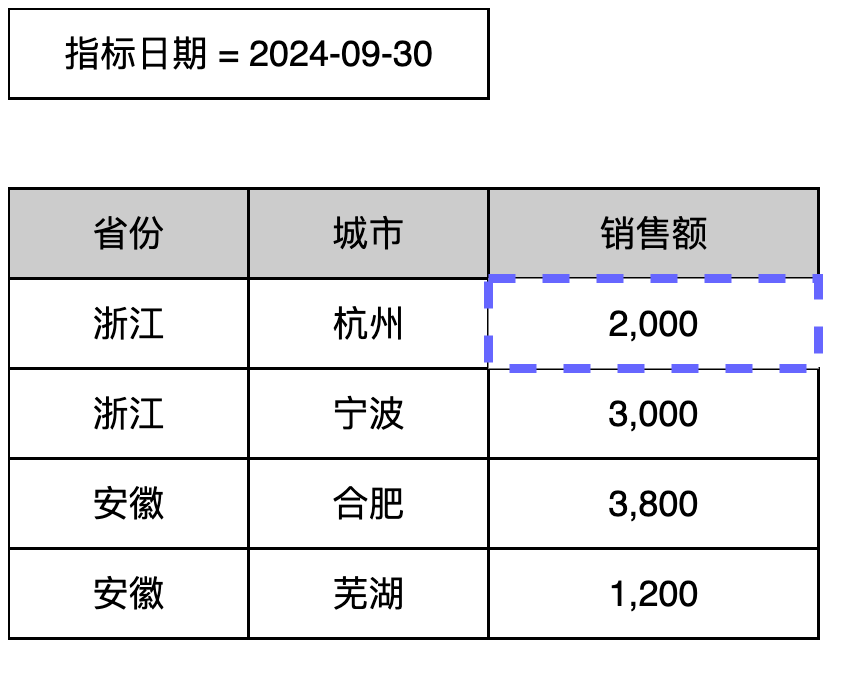
左图示例中的销售额指标结果,可以理解为有三个筛选作用:
指标日期=2024-09-30
省份=浙江
城市=杭州" 为了便于更简单的描述查询的运行环境,本文会将分组的维度理解为一个筛选维度。
左图示例中的销售额指标结果,可以理解为有三个筛选作用:
指标日期=2024-09-30
省份=浙江
城市=杭州 在有以上共识后,后续的查询环境的运算顺序都以筛选进行描述说明。
查询环境说明
当用户在界面中发起一个指标的结果查询时,由于指标的定义可能是多层嵌套的,比如派生指标引用基础指标,所以系统会生成多层嵌套的查询环境。
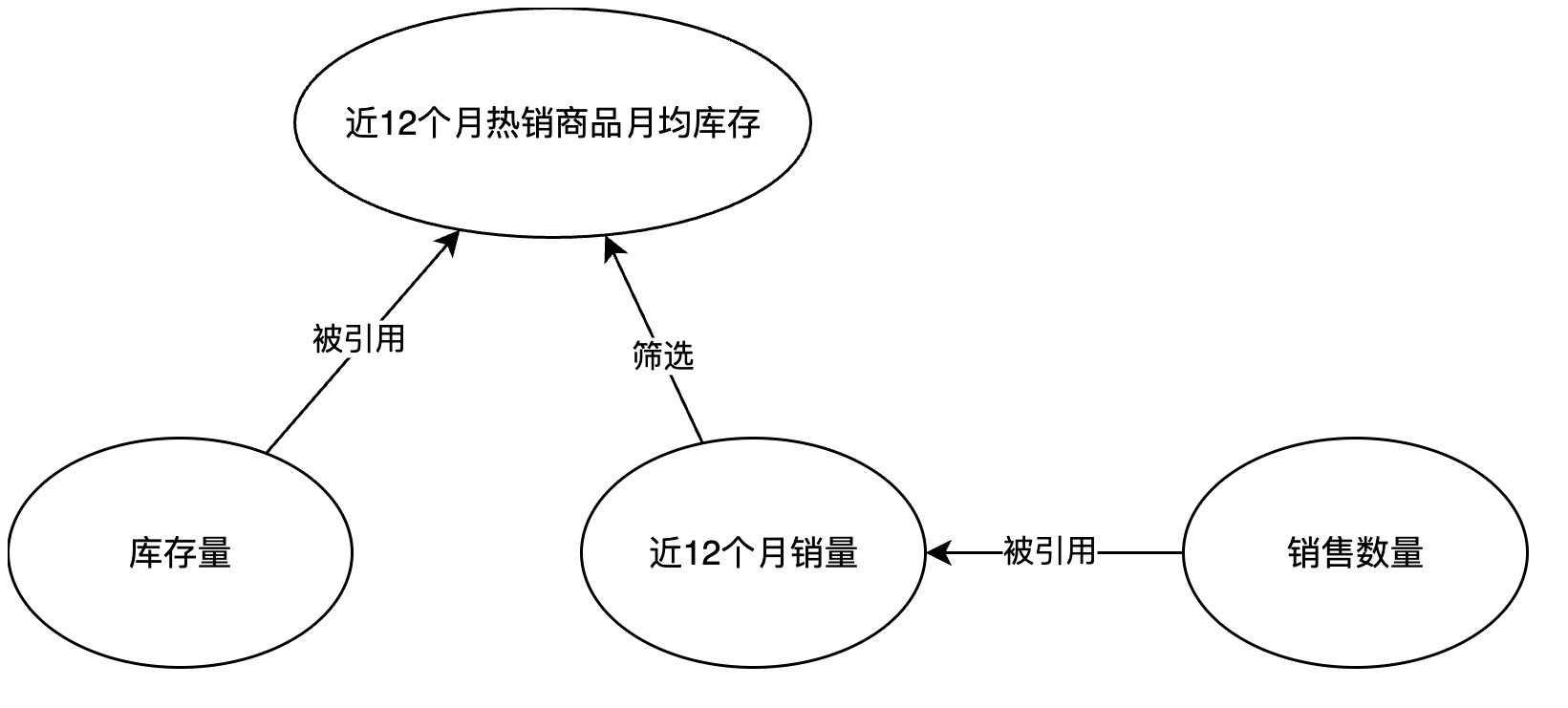
我们以一个稍微复杂一些的指标举例子,以下为指标定义
指标名称:近12个月热销商品月均库存量
类型:派生指标
基础/复合指标:库存量
时间限定:近12个月 月均值
业务限定:商品ID 满足 近12个月销量 > 1000
指标名称:库存量
类型:基础指标
统计内容:SUM( [库存量] )
半累加指标:开启
不可累加维度:日期
窗口选择:最大值
指标名称:近12个月销量
类型:派生指标
基础/复合指标:销售数量
时间限定:近12个月
指标名称:销售数量
类型:基础指标
统计内容:COUNT( [订单ID] )
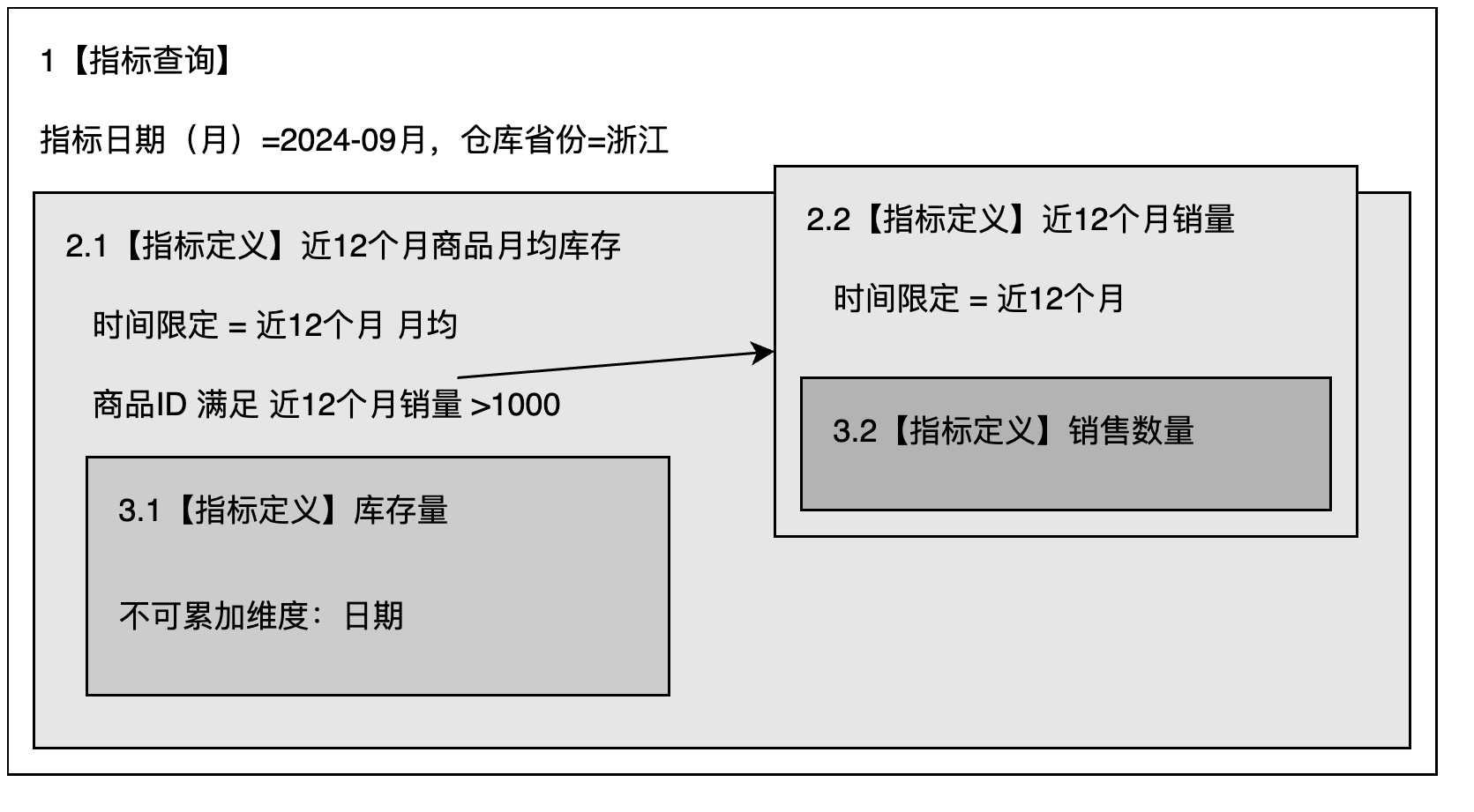
在指标查询中查询条件为:指标日期(月)=2024-09月、仓库省份=浙江。
则有以下示意图,表示查询环境的关系
规则
规则
-
查询环境由外向内传递,数据计算由内向外计算。
-
同层查询环境筛选条件互不影响
根据规则,我们来拆解这个查询的计算逻辑,生成查询环境
| 步骤 | 环境 | 处理逻辑 |
| 1 | 1 | 生成筛选条件: - 指标日期(月)=2024-09月 - 仓库省份=浙江 将该筛选条件传递给 2 |
| 2 | 2.1 | 接收1中的筛选条件,并融合自身的筛选条件 - 指标日期(月)=2024-09月 - 仓库省份=浙江 - 商品ID 满足 近12个月销量>1000 因为存在时间限定,所以会调整1中传递的指标日期 - 指标日期(月)=2023-09月 ~ 2024-09月 - 仓库省份=浙江 - 商品ID 满足 近12个月销量>1000 |
| 2.2 | 计算筛选 商品ID 满足 近12个月销量>1000使用到了 近12个月销量指标结果。从1中接收筛选条件- 指标日期(月)=2024-09月 - 仓库省份=浙江 因为存在时间限定,所以会调整1中传递的指标日期 - 指标日期(月)=2023-09月 ~ 2024-09月 - 仓库省份=浙江 |
|
| 3 | 3.1 | 接收2.1中的筛选条件 - 指标日期(月)=2023-09月 ~ 2024-09月 - 仓库省份=浙江 - 商品ID 满足 近12个月销量>1000 |
| 3 | 3.2 | 接收2.2中的筛选条件 - 指标日期(月)=2023-09月 ~ 2024-09月 - 仓库省份=浙江 |
按照以下步骤运行计算:
以 **指标日期(月)=2024-09月**、**仓库省份=浙江**的查询单元格为例进行推演:
在【3.2】环境内运算
- 按
商品ID作为分组维度,计算指标日期(月)=2023-09月 ~ 2024-09月、仓库省份=浙江的计算结果,得到多行数据
| 商品ID | 近12个月销量 |
|---|---|
在【3.1】环境内运算
-
按
指标日期(月)作为分组维度,计算指标日期(月)=2023-09月 ~ 2024-09月、仓库省份=浙江内的半累加指标 -
由于是半累加指标,筛选条件中存在不可累加维度
指标日期(月),所以指标会先在指标日期(月)范围内,保留最大的日期数据。 -
在上步过滤后的结果上,筛选
仓库省份=浙江并且将【3.2】中值>1000的商品ID保留,得到多行( 2023-09 ~ 2024-09 )数据
| 指标日期(月) | 近12个月热销商品库存量 |
|---|---|
- 将3中的数据结果计算平均值,得到最终结果
近12个月热销商品月均库存量