常见问题
Aloudata CAN支持哪些数据源?
请参考外部数据源
如何在 Aloudata CAN 中上传文件数据?
请参考本地文件上传
如何将外部的数据导入到 Aloudata CAN 中?
Aloudata CAN 使用的数据源为 Starrocks 或者 Doris,您可以参考内表数据导入,将数据导入到 Starrocks 或者 Doris 中。
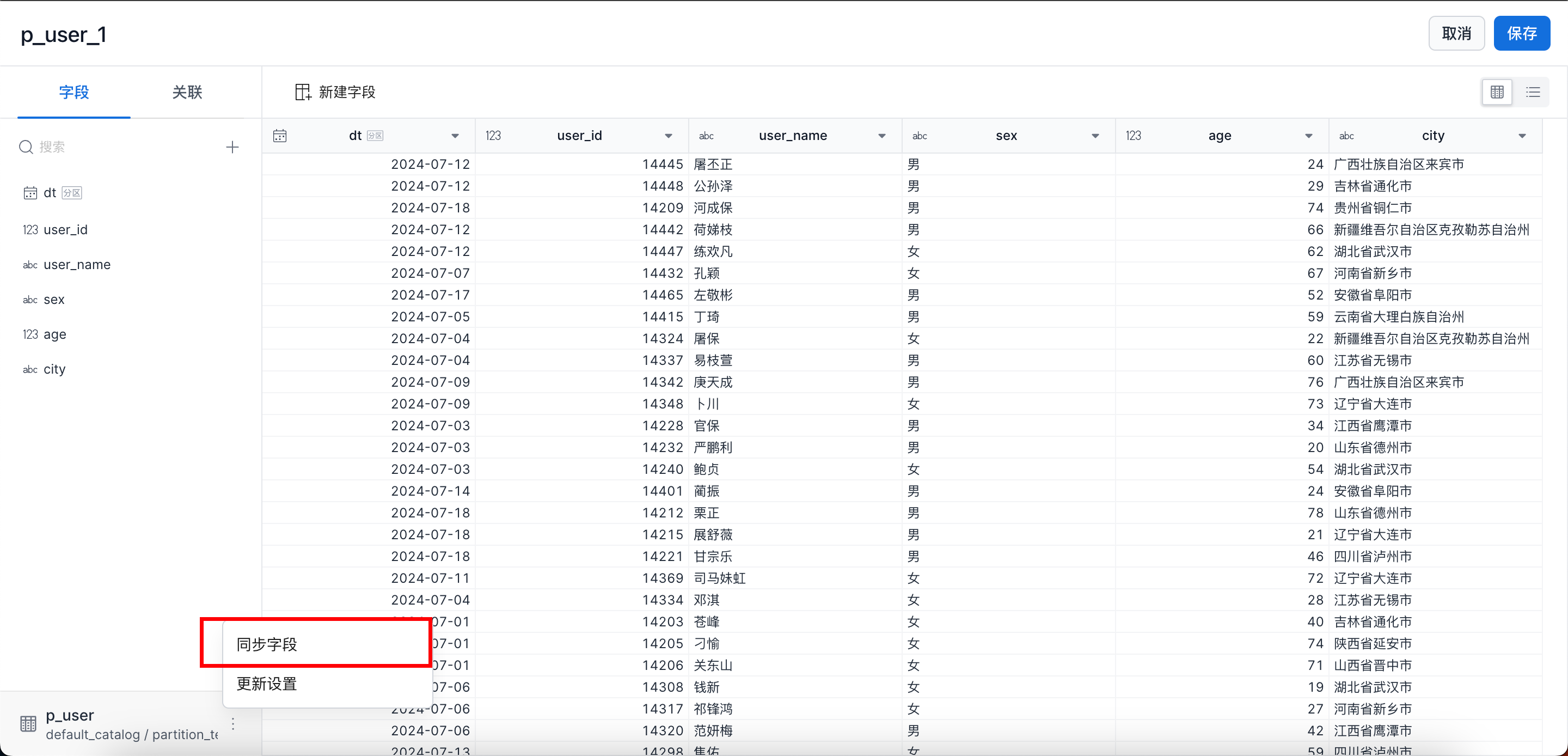
源物理表字段变更后如何更新下游的数据集模型?
可在数据集编辑页面,单击同步字段,可以将更新的字段再同步过来
如何配置数据集之间的关联关系?
参考设置数据集关系
如何让不同用户查看不一样的内容?
管理员或超管通过设置行级权限实现不同的用户查看不同的内容。请参见:行级权限
新建的物化加速方案会在第二天进行历史数据回补吗?
历史数据不会回补,但如果是分区数据,设置了分区增量更新,增量数据会在第二天自动回补。如需回补历史数据,请参考:回补物化数据
如何回补物化表的数据?
回补物化数据请参考:回补物化数据
如何手动更新物化数据?
详情请参考:管理物化表中的更新数据
指标逻辑的修改会触发加速方案的自动变更?
会触发
如何配置物化加速自动刷新数据的时间?
参考创建物化方案中的物化方案配置
BI工具与指标平台如何实现对接?
BI 工具与指标平台的对接请参考:BI 工具集成说明
指标的申请和审批流程可以怎么设置?
开启指标的申请和审批流程请参考:审批管理
Aloudata CAN 是否支持实时场景的查询?
支持,目前 Aloudata CAN 最小粒度支持到分钟的查询。最佳实践请参考实时场景指标查询
什么是基础指标、派生指标、复合指标?它们的区别是什么,
- 基础指标
基础指标 = 业务过程 +度量,定义业务过程和度量值的聚合逻辑,是最细的业务颗粒度,是具有明确业务含义的名词。例如,交易金额、实际施工产值等。特殊说明:如财务类已经在业务系统中计算好的指标也算作基础指标。
- 派生指标
派生指标=基础指标+时间周期+业务限定组成。派生指标是对基础指标业务统计范围的圈定。例如,本年累计交易金额、工程类_二级单位管理口径_施工产值_含税等。
- 复合指标
基于两个及以上基础指标或派生指标做二次多元计算的表达式。例如,若基础指标A和B,则可以定义复合指标C=A/B。例如,营业产值比、交易金额目标完成率、客单价等。
在 Aloudata CAN 对于派生指标定义的建议。
| 场景 | 是否提前定义 | 优势 | 劣势 |
|---|---|---|---|
| 1、业务限定的组合条件多(多层且或嵌套) 2、派生指标参与复合指标计算,且分子分母日期无法对齐 | 是 | 1、指标口径统一,不容易引起歧义 2、使用便捷 | 指标管理成本高 |
| 1、维度动态组合 2、业务限定简单,且不会引起用户歧义 | 否 | 指标管理成本低 | 1、容易引起用户歧义 2、用户消费门槛高 |
当前 Aloudata CAN 不支持的计算场景说明
年同比计算问题
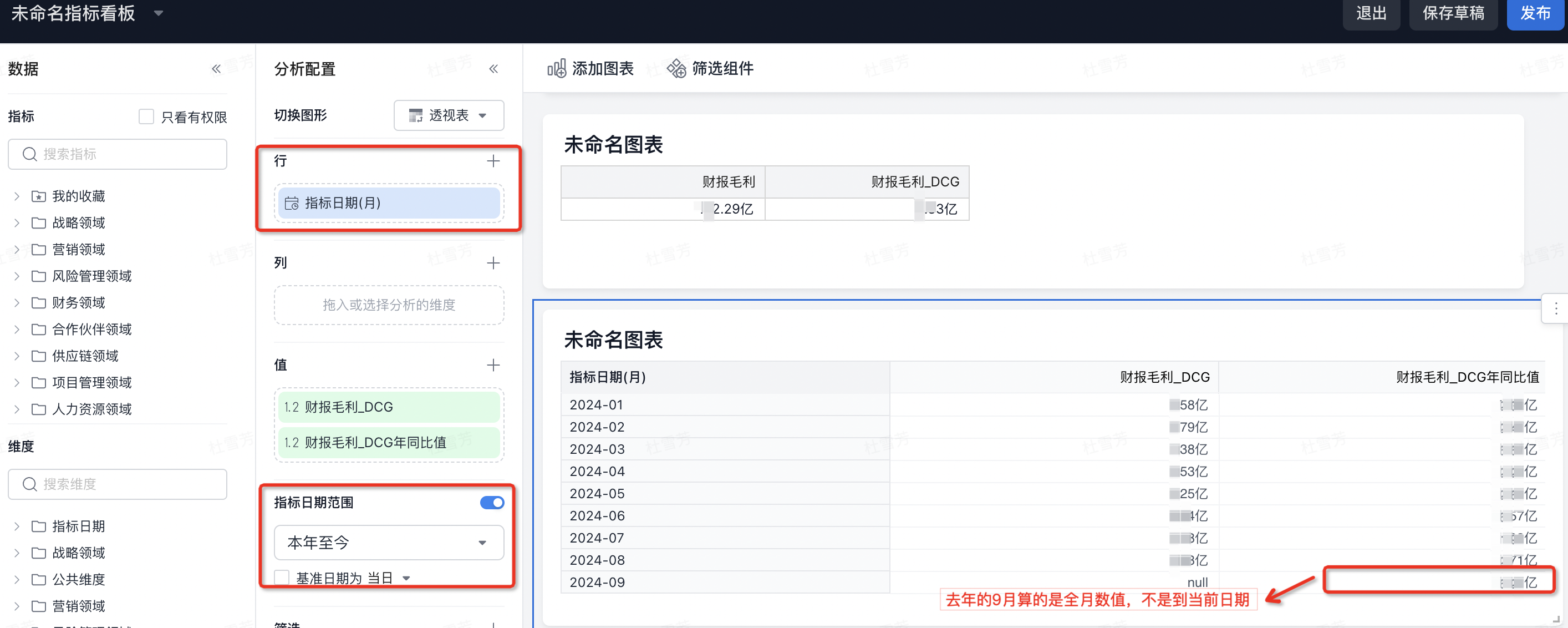
- 在进行年同比计算时,指标日期范围筛选【本年至今】,维度为【指标日期(月)】,目前只支持计算去年每月的整体数据,而不支持计算去年的本年至今的数据。如下图,假设今天是2024年9月25日,则2024年9月财报毛利_DCG年同比值计算的是2023年9月的整体数值,而不是2023年9月1~2023年9月25日的值。
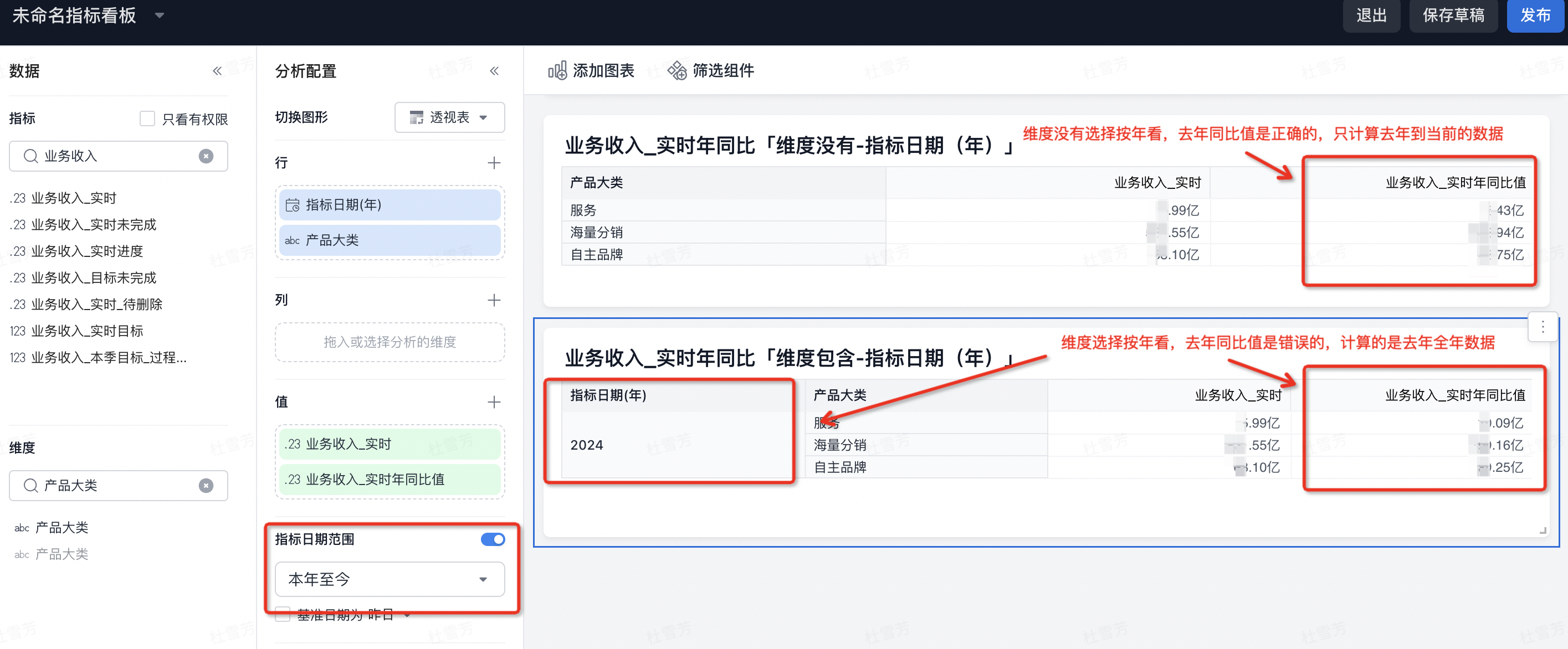
- 在进行年同比计算时,指标日期范围筛选【本年至今】,维度为【指标日期(年)】,目前只支持计算去年全年的整体数据,而不支持计算去年的本年至今的数据。如下图,假设今天是2024年9月25日,则2024年业务收入_实时年同比值计算的是2023年全年的数值,而不是2023年1月1~2023年9月25日的值。(短期解决方案:指标日期范围筛选【本年至今】,不将【指标日期(年)】作为分析维度,此时数据正确;长期产品上会考虑兼容这种场景)。
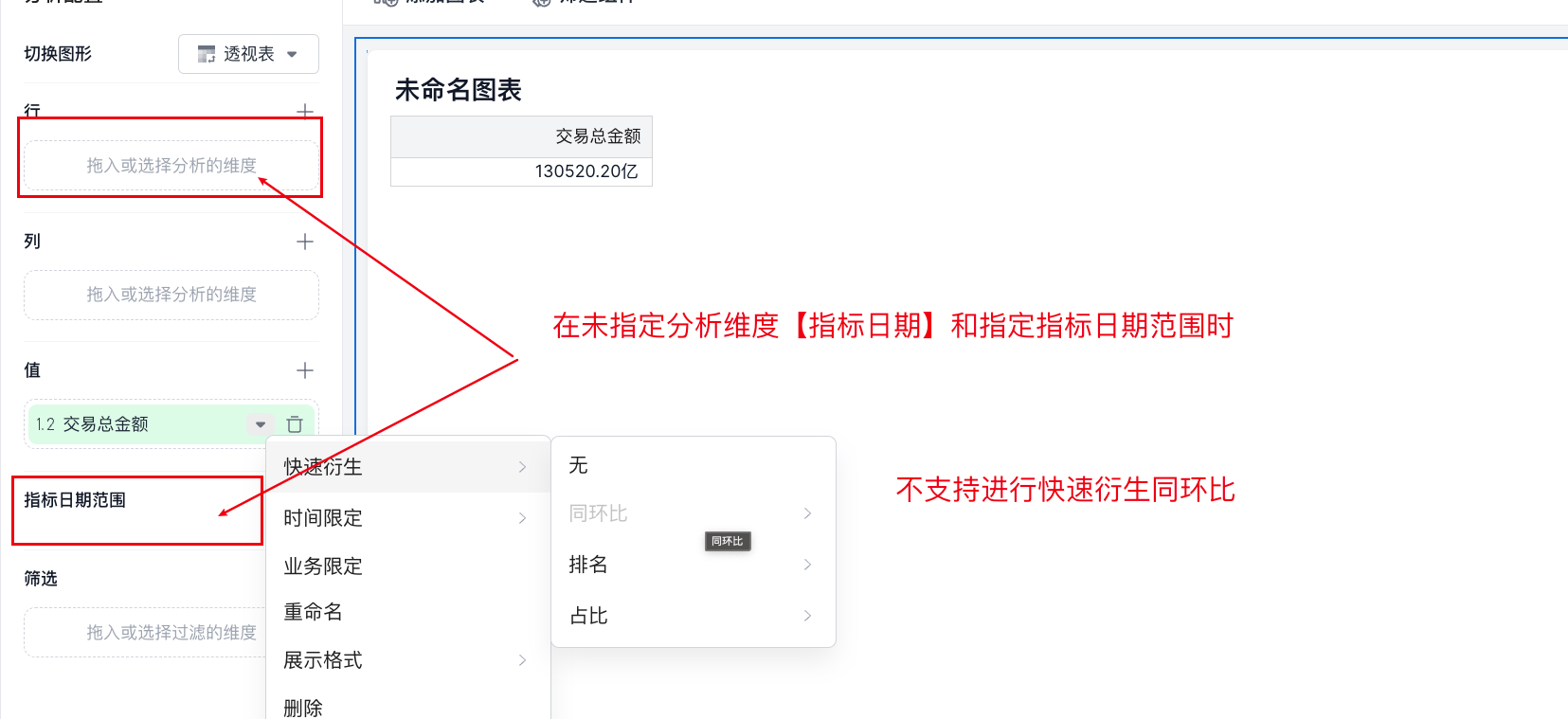
原子指标 + 同环比衍生+无日期【维度【无指标日期】或指标日期范围未筛选】
当前平台不支持在没有指标日期维度以及没有指定指标范围的情况下,直接使用原子指标进行同环比衍生计算。这种方式目前不支持。如下图示例。
多层嵌套指标
- 半累加指标 -> 先复合 -> 再多层派生: 目前平台不支持这种多层嵌套的计算方式。
如下图示例:其中【总金额比】为复合指标,由基础指标【交易总金额_1】/【交易总金额_2】得到,其中【交易总金额_1】为半累加指标。再基于该复合指标进行派生:获取 【1 年前当年_总金额比】。该场景目前产品暂不支持。
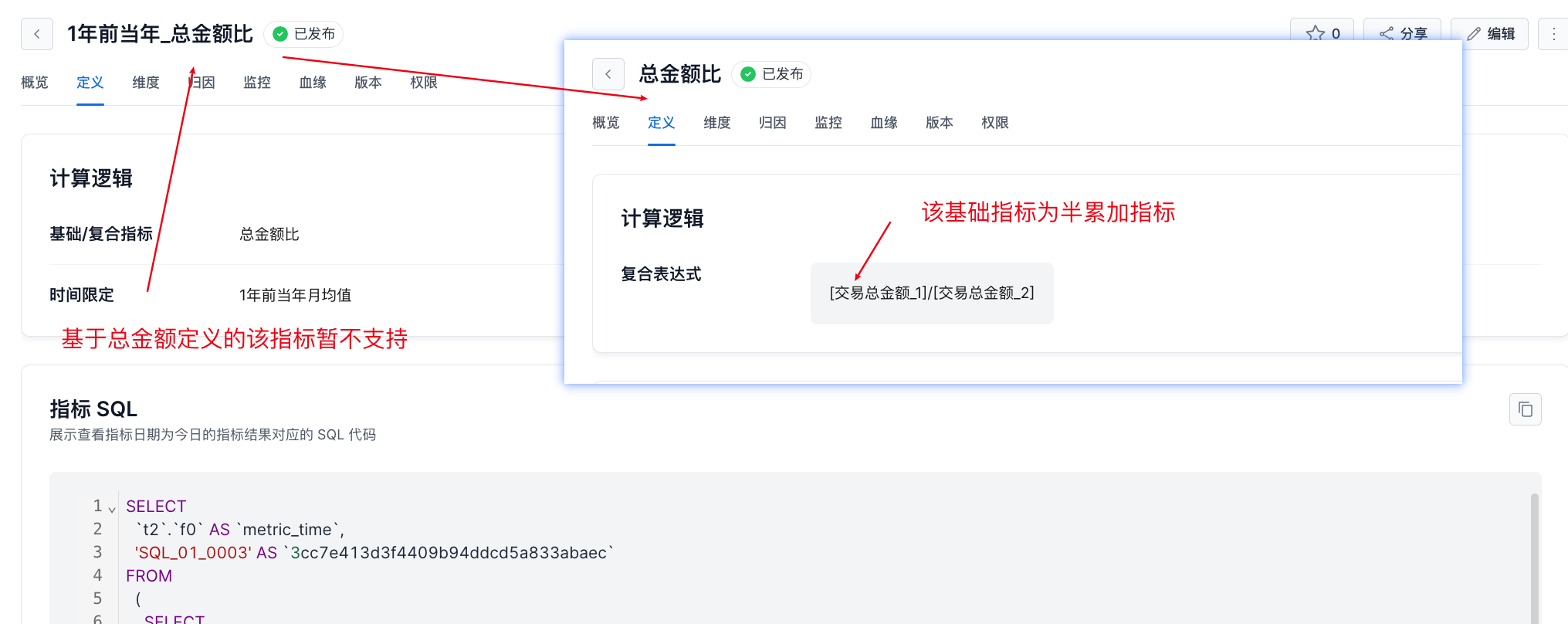
半累加计算问题
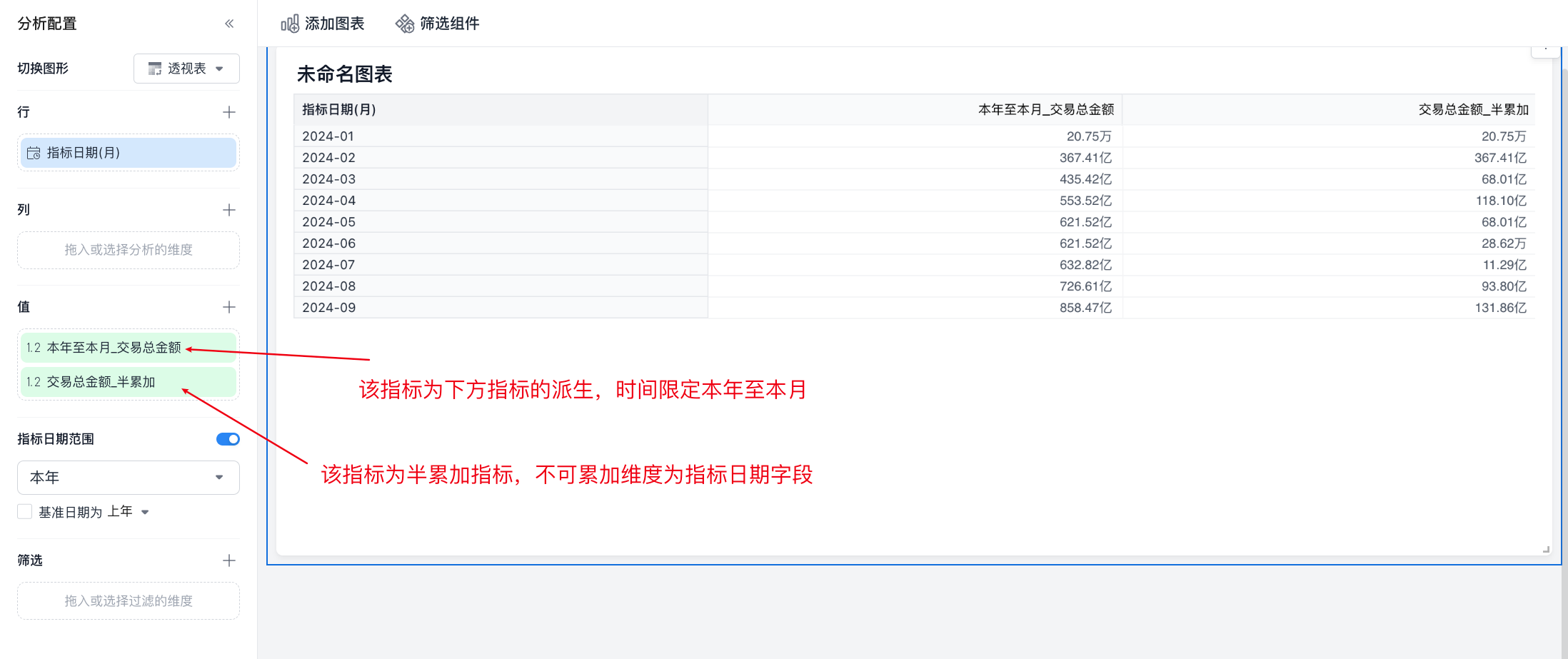
- 派生 + 半累加:
对【交易总金额_半累加】进行派生本年至本月计算时,维度为【指标日期(月)】。目前只支持按每月最大值进行逐月累加。不支持计算当前累计日期的最大值。例如下图中的数据,2 月份的数据为 1 月的半累加值+2 月的半累加值,以此类推;而不是计算 1-2 的最大值。
在 Aloudata CAN 中做了加速,为什么没有命中加速?没有命中该如何检查?
在进行数据查询和加速时,确保数据命中检查和命中策略的正确性是至关重要的。以下是详细的检查步骤和命中策略,以帮助用户更好地理解和应用。
数据范围检查
-
全量数据检查:确保全量数据已经被处理和检查过。
-
增量数据检查:对于增量数据,检查分区数据范围是否满足要求,即保障查询的日期范围在物化加速数据回刷范围内。
单层聚合命中
-
Count Distinct 查询:
-
如果查询包含
count(distinct),则加速的维度和查询的维度必须完全一致。 -
非 Count Distinct 查询:
-
如果查询不包含
count(distinct),则可以上卷命中已有的物化表,即查询的维度可以少于物化表的维度。 -
筛选条件:
-
筛选条件必须是维度字段的筛选。
多层聚合命中
-
维度一致性:
-
查询的维度和加速的维度需要保持一致。如果加速的是派生指标,则日期粒度可以不一致。例如,加速的是月粒度,而查询的是日粒度。
-
筛选条件:
-
筛选条件必须是维度字段的筛选。
如何在指标分析中选择适当的时间粒度?
我们在派生规则文档中介绍了不同时间粒度的派生指标及其对应的分析时间粒度选择。请参考该文档以获取详细步骤。
在 Aloudata CAN 首页“我的收藏”栏中指标卡片的查询逻辑是怎么样的?
关于首页“我的收藏”栏中指标卡片的查询逻辑,详情请见:首页指标查询逻辑。
在 Aloudata CAN 中是否支持多租户,以及如何新建一个租户?
Aloudata CAN 支持多租户架构,并提供租户之间的有效隔离。创建新租户请参考:新建租户。
读取 MySQL DATE/DATETIME 类型出现异常
这是因为 JDBC 中对于该非法的 DATE/DATETIME 默认处理为抛出异常,可以通过参数 zeroDateTimeBehavior控制该行为。
可选参数为: exception,convertToNull,round, 分别为:异常报错,转为NULL值,转为 "0001-01-01 00:00:00";
需要在创建 Catalog 的 jdbc_url 把JDBC连接串最后增加 zeroDateTimeBehavior=convertToNull ,如 "jdbc_url" = "jdbc:mysql://127.0.0.1:3306/test?zeroDateTimeBehavior=convertToNull" 这种情况下,JDBC 会把 0000-00-00 或者 0000-00-00 00:00:00 转换成 null,这样就可以正常读取了。
Doris 通过 JDBC Catalog 读取 IBM Db2 数据时出现 Invalid operation: result set is closed. ERRORCODE=-4470 异常
-
在创建 IBM Db2 Catalog 的 jdbc_url 连接串中添加连接参数:
allowNextOnExhaustedResultSet=1;resultSetHoldability=1。如: jdbc:db2://host:port/database:allowNextOnExhaustedResultSet=1;resultSetHoldability=1 -
如果引用的对象是 LOB,则最常见的原因是 LOB 值超出范围。可使用
progressiveStreaming属性设置为 2 来解决此问题。如;
dbc:db2://host:port/database:progressiveStreaming=2
结果加速和指标/明细加速的区别是什么。
为了优化数据查询性能,我们提供了两种主要的加速策略:结果加速和指标/明细加速。以下是这两种策略的适用场景、优缺点。
| 加速策略 | 使用场景 | 优势 | 劣势 |
|---|---|---|---|
| 指标/明细加速 | 适用于业务自助分析。 支持来自单个模型的指标加速。 | 适用范围比结果加速更广。支持二次上卷计算。例如,配置加速时使用了 D1、D2 维度和 M1 指标,查询仅涉及 D1 和 M1 时也能利用加速。 | 相对于结果加速,指标/明细加速的性能较差,但高于指标数据直接查询 |
| 结果加速 | 适用于固定报表的加速。 支持整合来自多个模型的指标。 | 性能卓越:提供最高效的查询速度。 | 要求物化表维度与查询请求完全一致,才能实现加速效果 |
在 Aloudata CAN 中结果加速机制变更影响说明。
1、 查询命中不受上游变更影响: 对数据源、数据集、指标或维度进行的任何上游变更,不会影响现有加速任务对查询的命中能力(但因新旧查询逻辑不一致,数据结果可能是错误的)。
2、 加速逻辑更新需“重新保存”: 为了确保加速任务使用最新的逻辑(例如,更新后的指标计算逻辑、维度定义或字段结构)来生成和查询加速数据,通常需要重新保存加速任务配置。
3、 物化视图重构需“重新保存”且“重构”: 某些特定的变更不仅需要重新保存配置,还需要重构底层的物化表,以确保其结构与新逻辑完全匹配。
主要影响及所需操作:
下表清晰说明了不同变更类型对加速逻辑和底层物理存储(物化表)的影响,以及您需要执行的操作:
| 变更场景分类 | 具体变更示例 | 对加速逻辑的影响 | 对物化表的影响 | 您需要执行的操作 | 操作说明 |
|---|---|---|---|---|---|
| ➤ 定义更新 | 修改指标的计算逻辑修改维度的定义 | 需更新加速逻辑以使用新的定义规则 | 无需重构 | 重新保存加速任务 | 确保加速按新逻辑计算 |
| ➤ 关键元素移除或者类型调整 | 从系统指标/维度列表中移除某个已被该加速任务使用的指标或维度 | 被移除元素不再有效,原有逻辑依赖中断 | 必须重构 | 重新保存加速任务,并重构物化表 | 清理无效配置;物理表需完全重建以移除依赖 |
| 在加速任务配置中主动剔除某个指标或维度 | 配置发生变化,不再包含该元素 | 必须重构 | 重新保存加速任务,并重构物化表 | 物理表需完全重建以排除该元素 | |
| 在数据集或数据源表中删除某个已被该加速任务使用的字段 | 底层数据缺失,原有加速依赖中断 | 必须重构 | 重新保存加速任务,并重构物化表 | 物理表需完全重建以移除对已删字段的依赖 | |
| 系统指标/维度的数据类型改变 | 配置发生变化,依赖中断 | 必须重构 | 重新保存加速任务,并重构物化表 | 清理无效配置;物理表需完全重建 |
关键总结与建议:
1、 查询命中无忧: 无论何种上游变更,现有加速任务都不会丢失查询命中能力。
2、 逻辑更新 = 重新保存: 任何定义或结构上的更改都需要重新保存加速任务配置,让加速引擎获知并使用新规则。这不会破坏现有物理表。
3、 移除元素或者类型变更 = 重建物理表: 任何涉及到已被加速任务实际使用的指标、维度的移除或者类型修改,都 不仅需要重新保存配置,还必须触发物化表的完全重构。这是因为原有的物理存储结构或内容已经包含无效或缺失的信息,必须彻底重建才能保证正确性。
当查询记录是运行中,怎么能够获取到查询SQL?
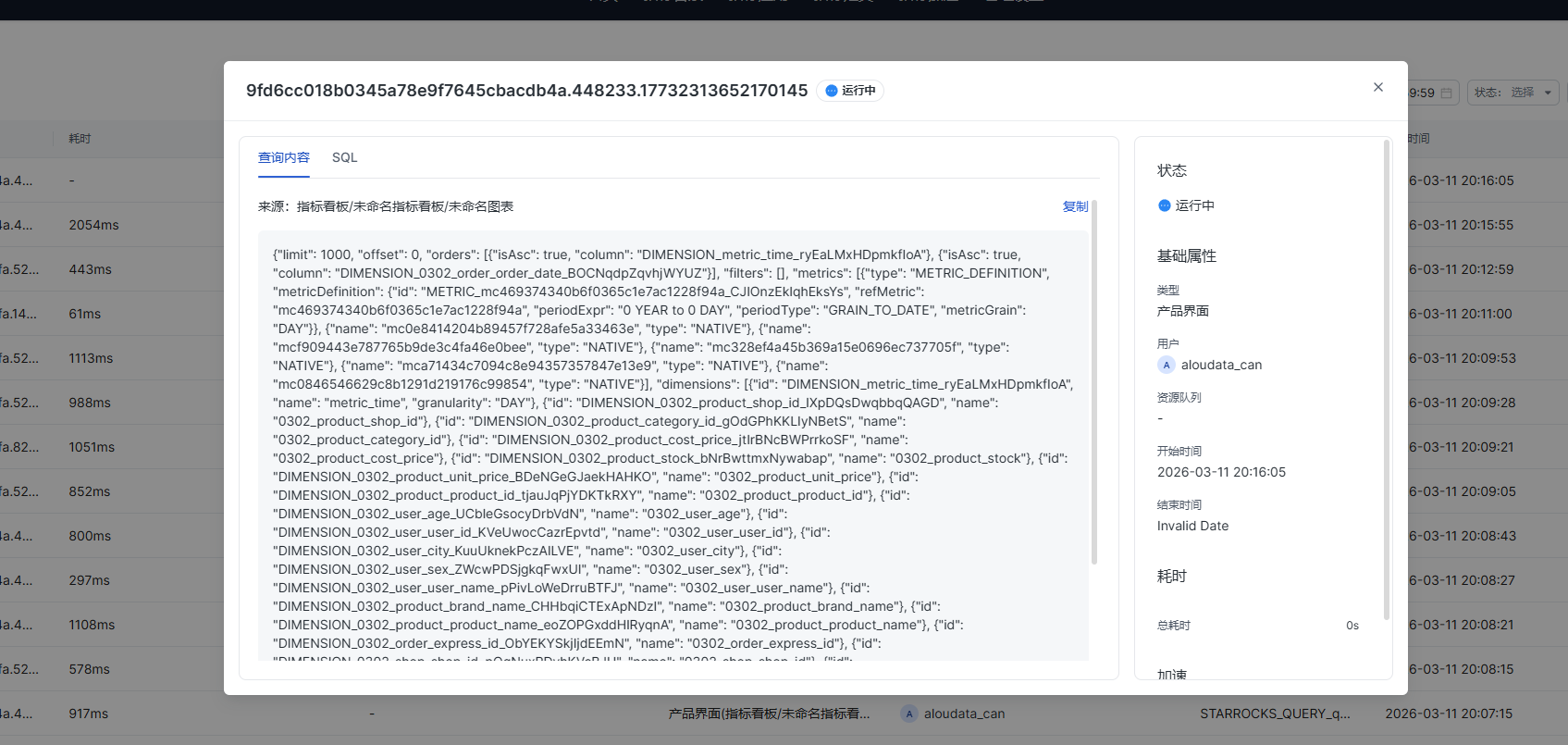
当查询记录在运行中时,可以通过以下方式获取到执行 SQL。
1、在查询记录中获取到查询内容。如上图示例;
2、通过在指标查询 API 中使用该请求内容+queryResultType=SQL 入参可以获取到执行 SQL。示例如下
curl --location --request POST 'http://127.0.0.1:8085/semantic/api/v1.1/metrics/query' \
--header 'tenant-id: xx' \
--header 'auth-type: UID' \
--header 'auth-value: xxxx' \
--header 'Content-Type: application/json' \
--data-raw '{
"limit": 4000,
"metrics": [
"sum_return_amount"
],
"dimensions": [
"metric_time__day"
],
"timeConstraint": "DateTrunc(['\''metric_time'\''], \"DAY\") = Now()",
"queryResultType": "SQL"
}'
关于指标查询 API 更多详情请见:指标数据查询