基础指标计算逻辑
概述
基础指标的定义中主要需要包含数据集、统计方式、指标日期标识和半累加指标的配置。本文将详细讲解每个配置的作用以及他们之间的运作机制。
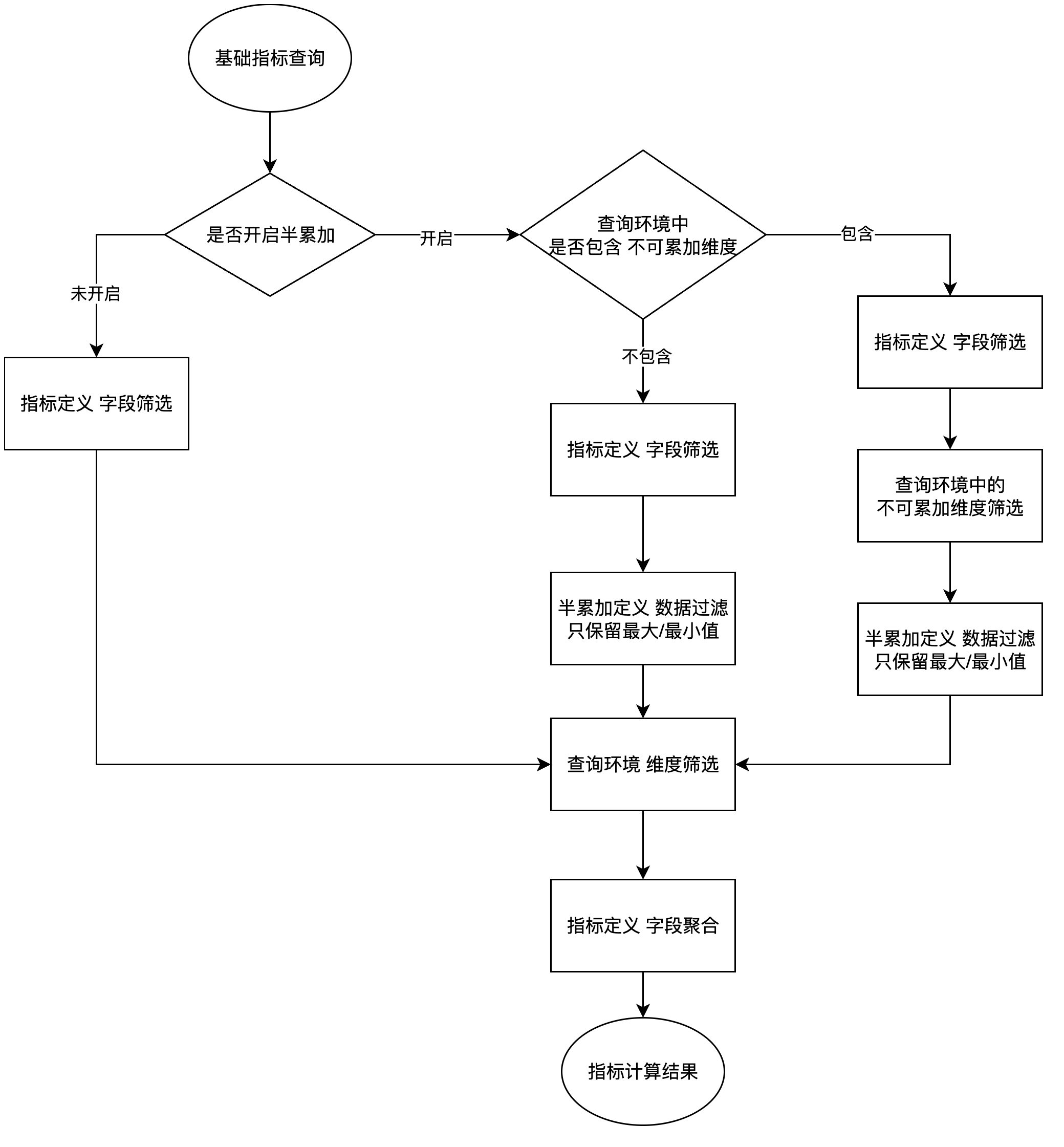
计算机制
常规基础指标
常规的基础指标是指没有开启半累加指标配置的基础指标。这类指标在查询时,会执行以下几个步骤:

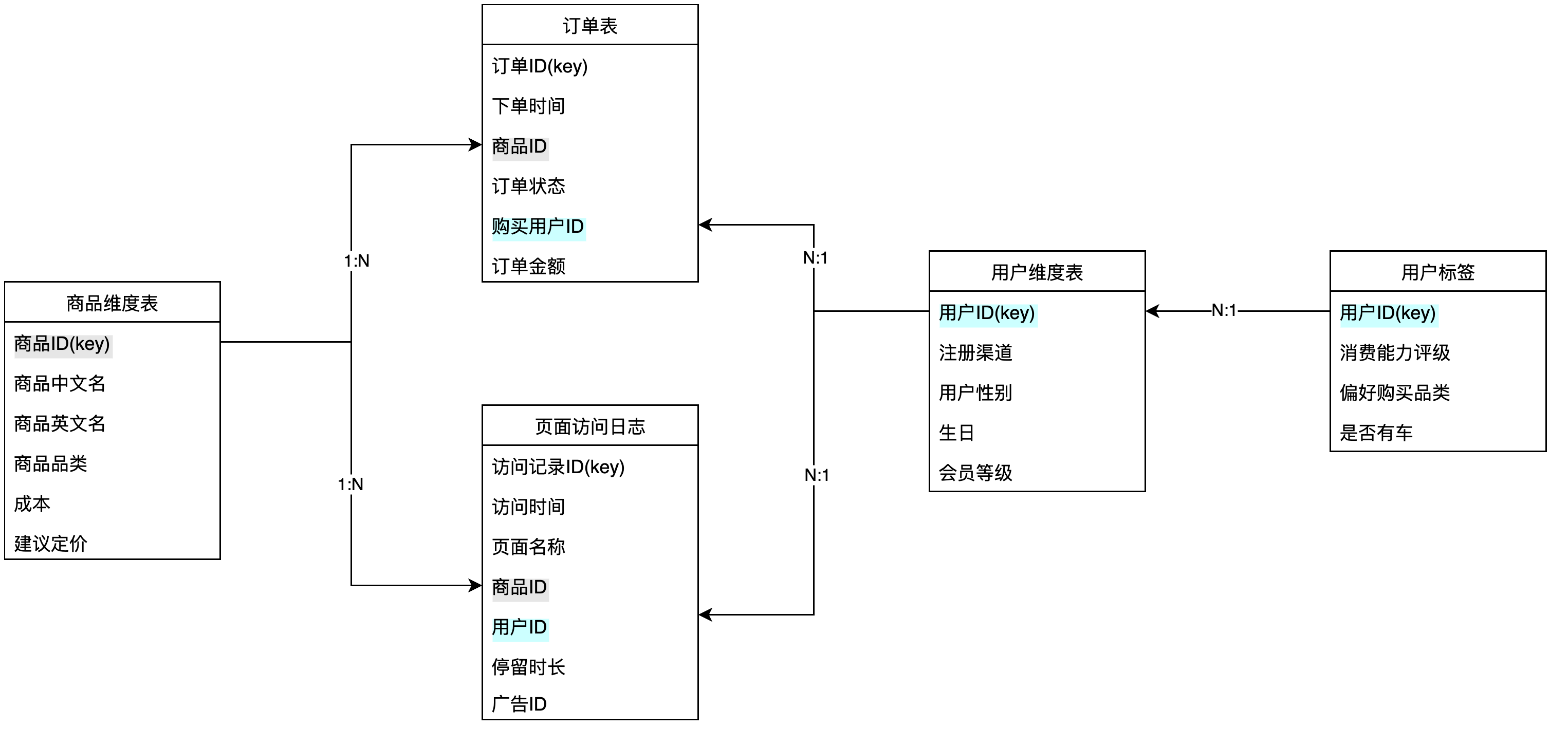
基于该数据模型,存在指标订单毛利润,其定义如下
指标定义配置: ● 数据集:订单表 ● 统计方式: SUM( [订单表/订单金额] - [商品维度表/成本] ) ● 指标日期标识:[订单表/下单时间]
查询 指标日期=2024-09-30、商品品类=电子产品 的 订单毛利润。
-
根据指标订单毛利润,确定查询的数据集为
订单表 -
根据查询环境中使用到的维度,确定需要使用
商品维度表和订单表来进行查询,将商品维度表中用到的数据与订单表关联。 -
将查询环境中的筛选作用于扩展后的
订单表中 -
指标日期根据配置转换为
[订单表/下单时间],筛选[扩展表/下单时间]=2024-09-30 -
商品品类维度转换为
[商品维度表/商品品类],筛选[扩展表/商品品类]=订单毛利润 -
基于筛选后的数据,执行指标的统计方式定义,
SUM([扩展表/订单金额]-[扩展表/成本])
半累加基础指标
半累加指标是一种特殊的基础指标。之所以称之为半累加指标,原因在于该指标在运算时,只会将满足特定条件的数据进行聚合。
举个例子,在银行行业进行数据分析时,用户存款金额是银行的一个重要分析指标。银行会每日0点生成一份用户存款快照数据,表结构如下:
| 日期 | 账户ID | 存折号 | 存款金额 |
|---|---|---|---|
需要注意的是:①每个用户可能会有多个存折;②用户销户后便不再更新其记录
业务分析时,希望可以按月份和开户行查看用户存款金额,以了解每个月每个行的存款业绩。
首先,每个月的用户存款金额不能像常规的指标一样将直接存款金额相加,因为如果直接相加,你会发现,用户的存款金额会变得很大。其根本原因是存款表是每日快照表,对于快照表的使用,我们应当甄别哪些可以聚合而哪些不可以。
以当前的存款快照数据为例,其中:
对于日期而言,不同日期的数据无法叠加。譬如不能将昨日的存款和今日的存款加和。
对于存折号或账户ID而言,是可以叠加的。譬如我们可以看不同支行的存款汇总数据,该数据集即将多个账户ID和存折号的数据进行了加和。"
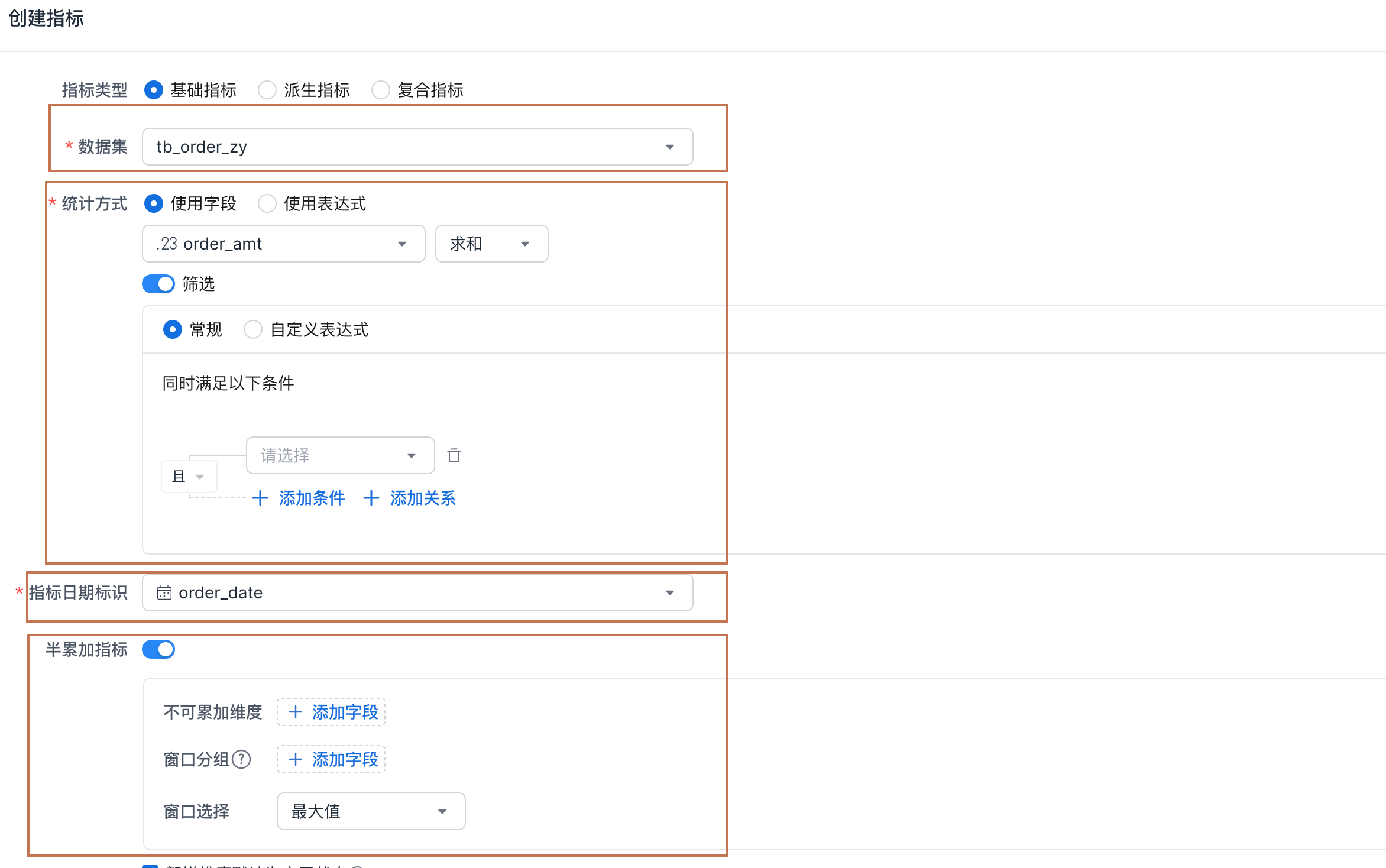
在指标平台中,可以通过配置半累加指标来实现上述的场景。
-
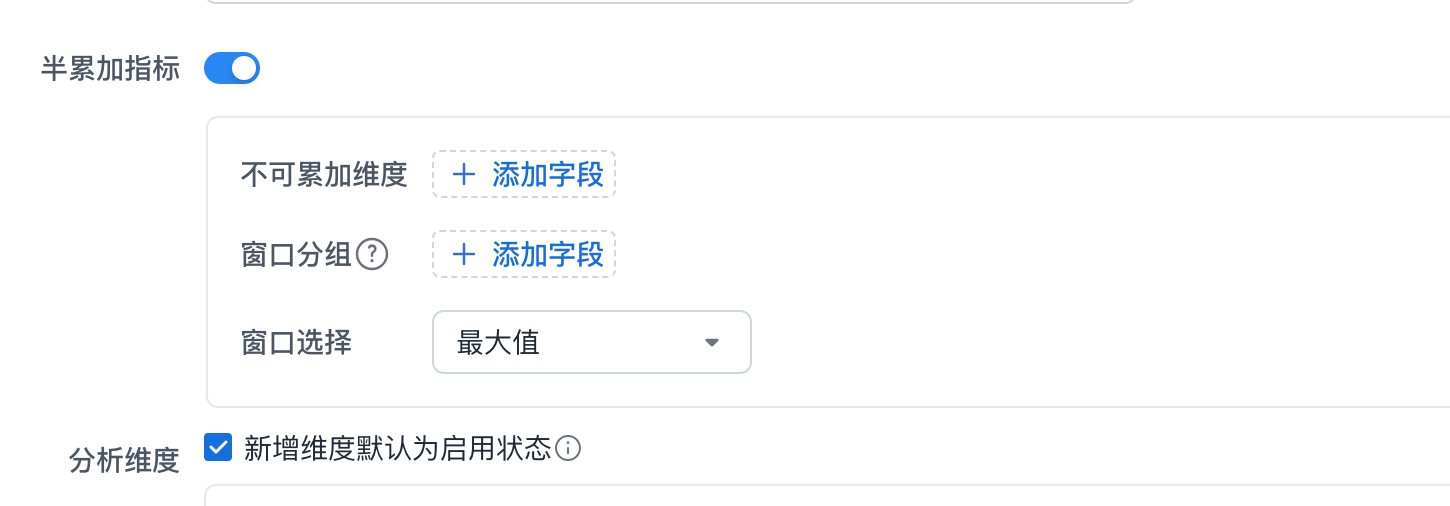
不可累加维度:即哪些维度在聚合时,不同的值不能放到一起聚合;基于上述的案例,
[日期]是不可累加的。 -
窗口分组:先将数据按窗口进行分组,再在窗口内选取满足的不可累加数据。(**目前不建议使用窗口分组功能**)
-
窗口选择:选择范围内的最大值或最小值。
当我们了解了半累加指标适用的场景后,我们来看半累加指标是如何运作的

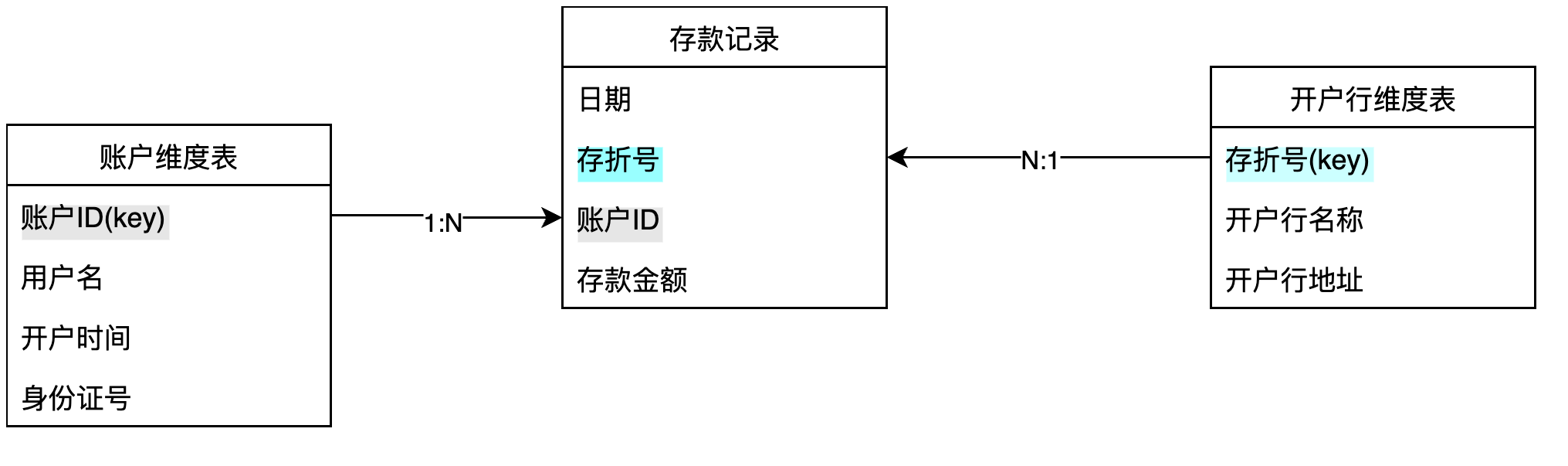
指标定义配置 数据集:存款记录
统计方式:
SUM([存款记录/存款金额])
指标日期标识:[存款记录/日期]
半累加指标:开启
不可累加维度:日期
窗口选择:最大值
查询以指标日期(月)、开户行名称作为分组,查询存款余额,希望看到每个月、每个开户行下的全部用户存款总额。
-
根据指标存款余额,确定查询的数据集为
存款记录 -
根据查询环境中使用到的维度,确定需要使用
账户维度表、开户行维度表和存款记录来进行查询,将两个维度表中中用到的数据与订单表关联。 -
由于指标是半累加指标,先获取查询环境中是否使用到了
[存款记录/日期],发现查询中使用到了该维度,执行该字段的筛选。
注意
这里需要注意一个逻辑,查询时使用指标日期和开户行名称是用于分组维度,而不是筛选;但是在运行时,我们可以认为他们是生成了多个组合的筛选值,对指标进行筛选。指标在每个维度值的组合条件下,依次计算生成指标结果。
以上只是将分组转化为筛选的逻辑理解,并不代表真实的代码构筑实现。
-
筛选
指标日期(月)=2024-09月,对步骤2中的扩展数据集进行过滤,只保留[存款记录/日期]=2024-09月的数据行。 -
执行半累加数据过滤:半累加的不可累加维度为
[存款记录/日期],且选取最大值;则在步骤3过滤后的数据结果上,仅保留[存款记录/日期]= MAX([存款记录/日期])的数据行。 -
执行其他的筛选条件,开户行名称的筛选在步骤4之后执行。
-
基于过滤后的数据,运算指标,生成指标结果。
总结